Druid 大數據實時處理的分布式開源系統
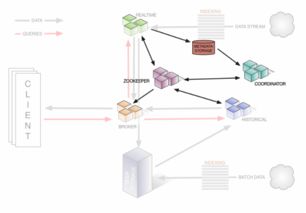
在當今數據驅動的時代,企業面臨著處理海量實時數據的巨大挑戰。Apache Druid作為一個開源的分布式數據處理系統,應運而生,專為快速查詢和分析大規模流式數據而設計。它結合了數據倉庫、時間序列數據庫和搜索系統的優勢,為實時監控、事件驅動分析、運營智能等場景提供了強大的支持。
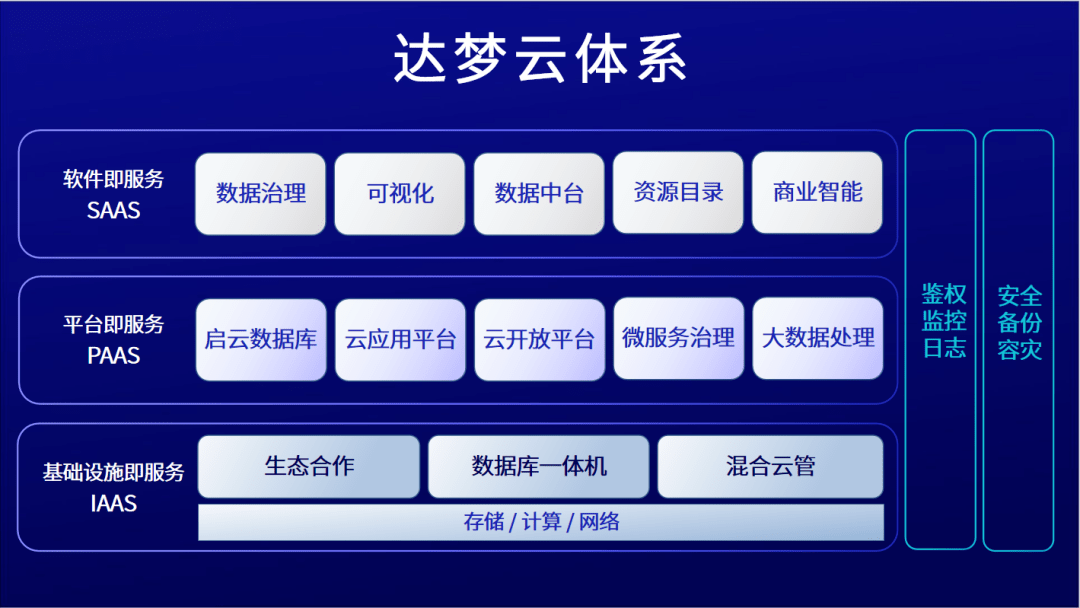
Druid的核心架構采用了分布式、可擴展的設計。其系統主要由協調節點、數據節點、查詢節點和歷史節點等組件構成,各司其職,協同工作。協調節點負責數據分片的管理和任務調度;數據節點處理實時數據攝取;歷史節點存儲和查詢歷史數據;查詢節點則接收并處理來自客戶端的查詢請求。這種模塊化設計使得Druid能夠靈活部署,并輕松應對數據量的增長。
在數據處理方面,Druid支持從多種數據源實時攝取數據,如Kafka、Amazon Kinesis等流式平臺,同時也支持批處理方式導入歷史數據。數據在攝取過程中會進行預聚合和索引,并采用列式存儲格式,極大地優化了查詢性能。Druid的查詢引擎支持低延遲的OLAP查詢,能夠快速完成復雜的數據聚合、過濾和分組操作,通常能在亞秒級內返回結果。
Druid的應用場景非常廣泛。在互聯網行業,它常用于用戶行為分析、廣告效果實時監控和A/B測試;在物聯網領域,可用于設備狀態監控和時序數據分析;在金融行業,則適用于實時風險控制和交易監控。許多知名公司,如阿里巴巴、Netflix和Airbnb,都在其數據架構中部署了Druid,以應對高并發、低延遲的實時分析需求。
Druid作為一個高性能的實時分析數據庫,以其卓越的查詢速度、可擴展性和可靠性,成為了大數據生態系統中不可或缺的一環。隨著實時數據處理需求的不斷增長,Druid將繼續演進,為更多企業提供強大的數據處理服務,幫助他們在數據洪流中捕捉價值,驅動智能決策。
如若轉載,請注明出處:http://m.njfgz.cn/product/14.html
更新時間:2026-05-28 10:12:54